线性回归
引言
在中学就学习过,一元线性回归
多元线性回归
损失函数
类似地,多元线性回归
正规方程
同样可以使用正规方程,求解
标量对向量的求导方法
进一步地,对于二次型
于是
二阶导
上面直接认定了代价函数有最小值,在这里我们可以向量对向量求导求海森矩阵而对于任意非零实列向量
令
带回到一元线性回归
对于
梯度下降法
就是让某组
联想到seurat
seurat里的特征缩放就是ScaleData()(特征内操作,不过seurat里行名才是特征),还有NormalizeData()的话(样本内操作),会除去不同样本之间数据尺度的影响(测序深度)。
适用于
模拟退火!
(注:后来发现,
逻辑回归
引言
线性回归中,数据沿着拟合的曲线分布。若某曲线为
损失函数
逻辑回归中引入了Sigmoid函数
这时就不能使用线性回归一样的损失函数了。
假如还是使用均方差
一通捣鼓下来算得(可以保留
- 当
时,若 ,这一项为负 - 当
时,若 ,这一项为负
所以这时损失函数就可能是非凸的,更多的可以看这些回答。
所以我们使用交叉熵损失函数
不行,再这样下去不懂春节期间能不能看完,接下来仅浏览
总之
决策树
以前一直瞧不起决策树,但是其实人力找出根据特征进行分类的方法是一种更低效的行为...
神经网络
比较好玩的是用神经网络实现逻辑门,比如对于2输入1输出的2层神经网络,输入
PS:递归神经网络很适合处理视频这样的时间序列数据,但deeplabcut里面好像没有涉及?我只看到他们多目标的top-down模型(目标识别分割->单独目标姿态识别)的第一步里,声称是使用了前后帧的信息。
PPS:感觉卷积神经网络和动物视觉很像?
聚类
无监督学习之一,让算法自己找出无标记数据集的结构然后把数据点进行分类。一般来说,我们想要簇中的数据点尽可能相似,而簇之间尽可能不同。
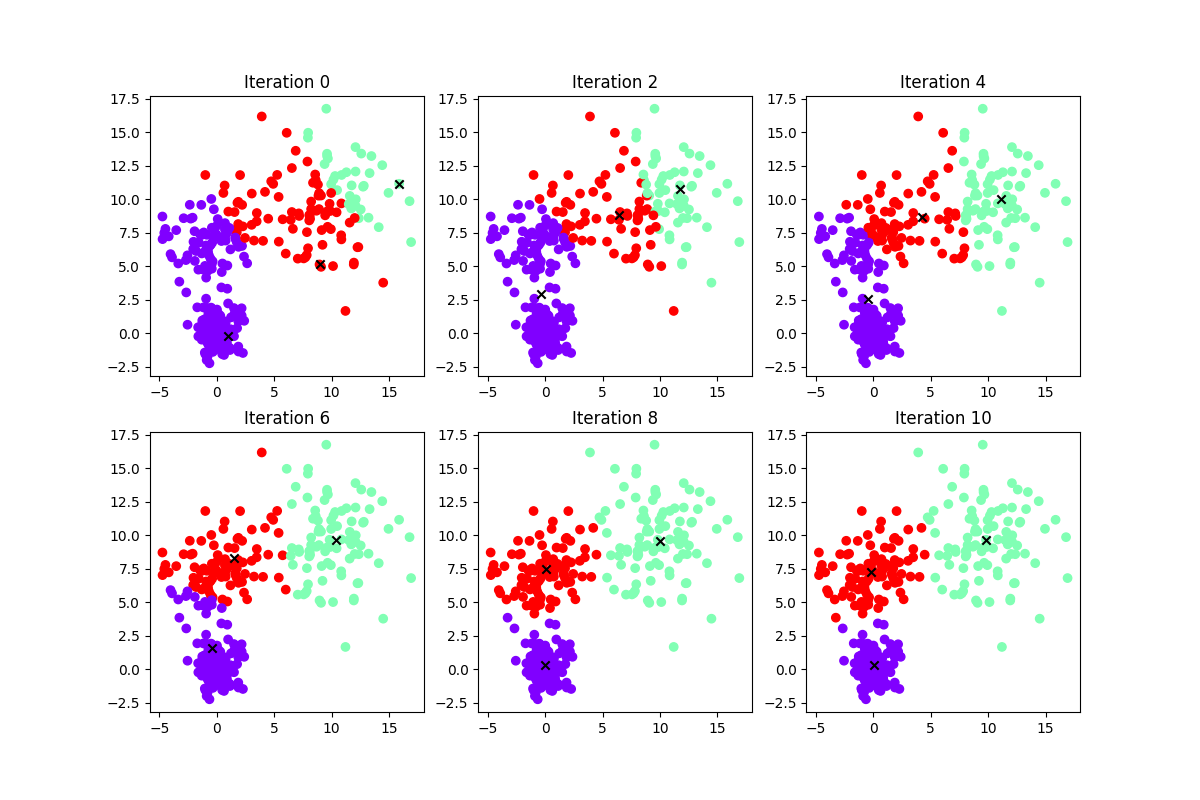
介绍一种朴素的方法:K-means,它的想法是指定簇的个数
具体可以这样实现:
- 随机选择
个数据点作为原型 - 迭代:
- 将数据点划分为最近原型对应的簇
- 更新每个原型为其簇的中心
下面是一个高斯混合分布生成的二维数据的例子:
1 | import numpy as np |
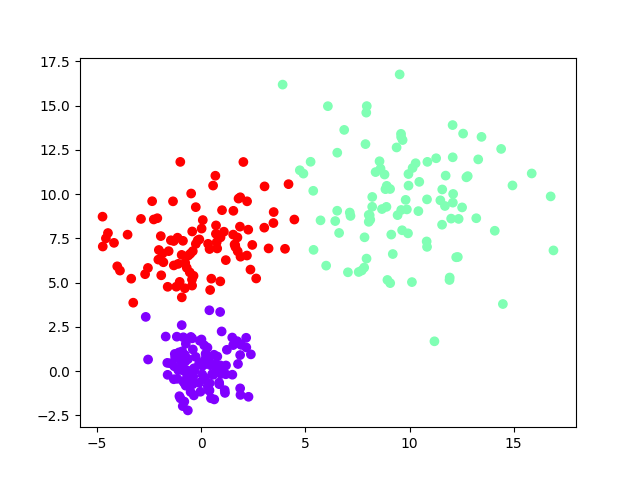
每个簇之间由中心连线的中垂线分隔,很显然这种方法有时无法产生非凸的簇(比如说,一个簇环绕着另一个簇),而且在大簇旁边有小簇的情况下,效果可能并非预期。
这是迭代过程
而seurat使用的聚类方法类似于:
- 计算k近邻图(k-Nearest Neighbor
Graph):一种朴素的方法是,先计算每个细胞到距离(多种方法)最小的
个细胞的有向无权图,然后根据有无边生成无向无权图 - 计算共享近邻图(Shared Nearest Neighbor Graph):对于每条边,计算两端细胞的Jacard相似度(二者共同邻居数/二者总邻居数),生成无向有权图(还可以删掉一些权值较小的边)
- 如果使用Louvain算法:初始化每个细胞为一个community,迭代:遍历每个细胞,根据模块度(Modularity)将其贪心地加入相邻community
降维
多维缩放
MDS(骨髓增生异常综合征),目标是将高维的原始样本空间映射到低维的特征空间的同时,尽量保留原始的距离关系。
有两种方式可以实现:
- 最小化应力函数(样本在低维空间和原始空间的距离差异)
- 通过原始空间的距离矩阵计算低维空间的内积矩阵,然后进行特征值分解,取最大的几个特征值构成的对角矩阵和相应的特征向量矩阵,计算低维空间的新坐标
主成分分析
在原始空间中找到一些向量构成基的一部分,把数据点投影在这些向量构成的(超)平面上,使用这些向量的线性组合来表示新坐标
- 最大化投影后数据点的方差
- 最小化投影前后数据点的差异。
最后都能得到最大化
将原始数据中心化、标准化之后,计算协方差矩阵,可以进行特征值分解,和上面的多维缩放一样取最大的构成投影矩阵;也可以进行奇异值分解得到U和S,取最大的S的成分和对应的U构成投影矩阵,其中